Although we live in a 3D world, we aren’t always very good at judging the volumes of things. A few years ago I had the idea of exploring our (mis)judgements of volume by making a collection of differently-shaped objects, all of which had a volume of a pint. I didn’t do anything about it at the time, but when I discovered recently that Pint of Science in Glasgow was holding Creative Reactions, an art exhibition, I decided to take the hint and get to work.
Cuboids
These cuboids all have a volume of a pint.
Optimal shapes
These shapes not only have a volume of a pint, but they are all optimal in terms of surface area:
Of all the cuboids with a volume of a pint, a cube has the smallest surface area. Of all the cylinders with a volume of a pint, a cylinder whose height and diameter are equal has the smallest surface area. Of all the cones with a volume of a pint, a cone whose height is the square root of 2 times its base diameter has the smallest surface area.
And of all solid shapes with a volume of a pint, a sphere has the smallest surface area.
I made the cylinder, sphere and cone on a lathe, and the sphere on a bandsaw.
A quiet pint
Here we have the lowest (most distal) pint of my arm and hand about to pour a pint of beer into the front pint of my face. All the beer-glass shapes are casts of the interiors of pint glasses. I was slightly disappointed by the beer-glass casts; I was hoping that they might seem strikingly small compared to the actual filled beer glasses, but they don’t.
Casting was a new venture for me. My thanks to Amy Grogan and Alys Owen of the casting workshop at Glasgow School of Art for their help and advice.
My thanks also to Laura McCaughey, Marta Campillo Poveda, and Danielle Leibnitz, who organised the exhibition.
Wandering the mountains of the UK has been a big part of my life. You won’t be surprised that before I start a long walk I like to know roughly what I’m letting myself in for. One part of this is estimating how far I’ll be walking.
Several decades ago my fellow student and hillwalking friend David told me of a quick and simple way to estimate the length of a walk. It uses the grid of kilometre squares that is printed on the Ordnance Survey maps that UK hillwalkers use.
To estimate the length of the walk, count the number of grid lines that the route crosses, and divide by two. This gives you an estimate of the length of the walk in miles.
Yes, miles, even though the grid lines are spaced at kilometre intervals. On the right you can see a made-up example. The route crosses 22 grid lines, so we estimate its length as 11 miles.
Is this rule practically useful? Clearly, the longer a walk, the more grid lines the route is likely to cross, so counting grid lines will definitely give us some kind of measure of how long the walk is. But how good is this measure, and why do we get an estimate in miles when the grid lines are a kilometre apart?
I’ve investigated the maths involved, and here are the headlines. They are valid for walks of typical wiggliness; the rule isn’t reliable for a walk that unswervingly follows a single compass bearing.
On average, the estimated distance is close to the actual distance: in the long run the rule overestimates the lengths of walks by 2.4%.
There is, of course, some random variation from walk to walk. For walks of about 10 miles, about two-thirds of the time the estimated length of the walk will be within 7% of the actual distance.
The rule works because 1 mile just happens to be very close to kilometres.
The long-run overestimation of 2.4% is tiny: it amounts to only a quarter-mile in a 10-mile walk. The variability is more serious: about a third of the time the estimate will be more than 7% out. But other imponderables (such as the nature of the ground, or getting lost) will have a bigger effect than this on the effort or time needed to complete a walk, so I don’t think it’s a big deal.
In conclusion, for a rule that is so quick and easy to use, this rule is good enough for me. Which is just as well, because I’ve been using it unquestioningly for the past 35 years.
Suppose we have a floor made of parallel strips of wood, each the same width, and we drop a needle onto the floor. What is the probability that the needle will lie across a line between two strips?
Let’s recast that question a little and ask: if the lines are spaced 1 unit apart, and we drop the needle many times, what’s the average number of lines crossed by the dropped needle? It turns out that it is
where l is the length of the needle. Now add another set of lines at right angles (as if the floor were made of square blocks rather than strips). The average number of lines crossed by the dropped needle doubles to
Can you see the connection with the distance-estimating rule? The cracks in the floor become the grid lines, and the needle becomes a segment of the walk. A straight segment of a walk will cross, on average, grid lines per kilometre of its length. Now a mile is 1.609 kilometres, so a segment of the walk will, on average, cross grid lines per mile, which is very close to 2 grid lines per mile, as our rule assumes. If a mile were km (1.570… km), we’d average exactly 2 grid lines per mile.
So the fact that using a kilometre grid gives us a close measure of distance in miles is just good luck. It’s because a mile is very close to kilometres.
In a future post, I’ll explore the maths further. We’ll see where the results above come from, and look in more detail at walk-to-walk variability. We’ll also see why results that apply to straight lines also apply to curved lines (like walks), and in doing so discover that not only did the Comte de Buffon have a needle, he also had a noodle.
When you stir a cup of tea, the surface of the rotating liquid develops a dip in the middle. The faster you stir, the deeper the dip. But the liquid surface is quite uneven; to get a smooth surface, throw the spoon away and spin the whole cup continuously. Once the liquid inside has caught up with the cup, and everything is turning at the same speed, the liquid surface forms a beautiful smooth curve known as a paraboloid of revolution.
Sarah McLeary and I are applying this idea to make thin paraboloidal plaster shells. We spin a bucket on a potter’s wheel (Sarah is a potter), and pour plaster into it. The plaster rapidly flows until its surface forms a deep paraboloidal curve, and then sets. We now use this cast, still spinning, as a mould, and cast a thin layer of plaster inside it, to make a paraboloidal shell.
That’s our first attempt above. It’s about 20 cm across and 3 mm thick. It might look like a part of a sphere, but in a profile view it’s easy to see that the curvature is tightest at the base and gradually decreases up the sides, as you’d expect for a paraboloid.
I love the fact that we didn’t decide what shape this shell was going to be: physics did.
There’s lots of experimentation ahead. When we’ve got the hang of it, I’ll explain our methods in more detail. But as this picture of our third attempt shows, we haven’t quite cracked it yet.
Last week I was on holiday in Wales. It wasn’t the driest of weeks, and while I was inside not climbing mountains, I finally got round to doing some mountain-related geometry that I’ve been putting off for the last 30 years or so. It’s about knowing how high you are.
Am I higher or lower than the summit in the middle distance? (The peak of Hellaval on the island of Rum, taken from the flanks of Askival, with Skye in the background)
If you’re climbing or descending a mountain, you sometimes want to know roughly how far (vertically) there is still to go. One way to get an idea of your altitude is to use nearby peaks or other points of known altitude as reference points. But how do you judge whether you are above or below another point? It’s not always obvious, and without some sort of rule, the worry is that you’ll make optimistic judgements, leading to disappointment in the long run.
My friend Malcolm once told me that, as a rule of thumb, you should look at the reference point relative to the distant skyline. If the point appears to be above the skyline, you are lower than it, and if it appears to be below the skyline, you are higher than it. I’ve used this skyline-rule ever since, but I’ve never checked how accurate it is.
The fact that there’s any doubt about the rule is because the Earth is not flat. If it was flat, then your line of sight to the (infinitely distant) sea-level horizon would be exactly horizontal, and the rule would work perfectly. If the skyline was made up of mountains, the rule would work perfectly as long as they were as high as your reference point.
But the Earth isn’t flat: it’s a big ball. How does this affect the accuracy of the rule? I used a wet Welsh Wednesday afternoon to find out.
It turns out that the rule is good enough for general hillwalking purposes as long as the reference point is no more than two or three kilometres away (as it usually will be). The errors are smaller if the skyline is distant mountains rather than the horizon at sea level. The rule consistently underestimates your altitude, which, in ascent at least, is probably better than the alternative. Continue reading How high am I ?
In a previous post I showed some examples of irregular polyhedra that I’ve been making out of paper. These polyhedra were all based on points distributed quasi-randomly over a sphere. At each point, my program placed a plane tangent to the sphere. The result of the intersection of all of those planes was an irregular polyhedron.
The 47-hedron in the picture above was made in a rather different way. It’s certainly irregular, but the process that created it was not at all random. As in the previous polyhedra, the starting point was a sphere with a number of points distributed over it. But this time, the points were placed according to a simple and perfectly regular rule.
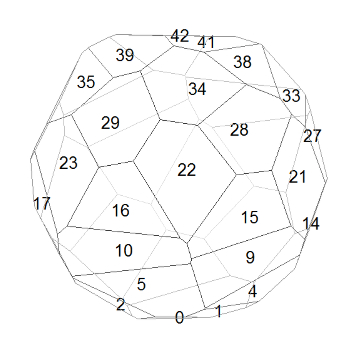
Imagine you you draw a line from one pole of a sphere to the opposite pole, winding sort-of-helically around the sphere. Then place a number of points at exactly equal spacings along this line. In the examples below, there are 43 points.
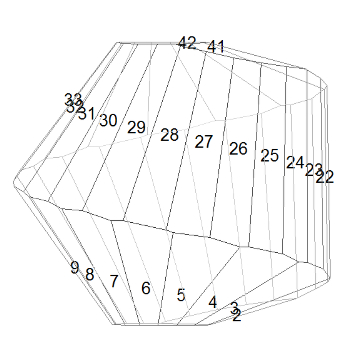
If your quasi-helix had 2.5 turns, the result would look like the diagram on the right. The numbers are where the points are placed on the imaginary sphere; the resulting polyhedron is also drawn. The helical structure is very clear, but notice the irregularity of the faces: for example, the lower edges of faces 26, 27, and 28 are all different. This is because the radius of the quasi-helix is not constant, so turns of the helix near the poles will have fewer faces on them than turns near the equator, which means that the way the numbers on one turn line up with the numbers on the previous and subsequent turns keeps changing.
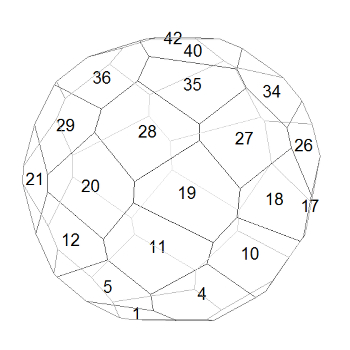
If we increase the number of turns in the quasi-helix to 5, the helical structure is still clear:With 7.5 turns in the quasi-helix (below), adjacent-numbered faces are now so far apart that the faces on the turns above and below them are starting to intrude into the spaces between them. See, for example, how faces 27 and 28 are almost pushed apart by faces 19 and 35.By the time we have 10 turns (below), consecutively-numbered faces are so far apart that faces from the turns above and below often meet between them, making the helical structure hard to discern (see, for example, how faces 34 and 22 squeeze in between faces 28 and 29). The polyhedron is beginning to look quite irregular, but note that consecutively-numbered faces are still more similar to each other than they are to the other faces.
The 47-hedron on the right (same as at the top of the post) was based on a quasi-helix with about 12.5 turns. At first sight, it looks quite random, and it’s certainly irregular, but there are still visible similarities between faces if you look hard enough. Compare, for example, the mid-blue and light-blue faces at roughly 10 o’clock and 2 o’clock respectively. And what about the dark-blue and very dark-blue faces just below the centre? One looks suspiciously like a rotated version of the other – and it is! In fact the whole polyhedron has an axis of 180° rotational symmetry. This suprised me when I spotted it, but it shouldn’t have. A helix has 180° rotational symmetry (turn a corkscrew upside down and it looks the same) so it’s inevitable that shapes based on a helix will have that symmetry also.
It’s a remarkable fact that there are only five regular convex polyhedra, that is, solid shapes whose flat faces are all identical regular polygons. The most familiar example is the cube, with 6 identical square faces. There are other, less regular but still orderly polyhedra, such as the truncated icosahedron, seen in a bloated form in some footballs.
But what, I wondered, about truly irregular polyhedra, where every face is a different irregular polygon? What would they look like? Last January I set out to make some and find out.
My irregular polyhedra are all based on spheres. Imagine placing a number of dots on a sphere. At each dot, let there be a plane just touching the sphere. These planes will all intersect each other, and if we remove the parts of each plane cut off by the neighbouring planes, we’re left with a polyhedron, with one face for each dot that we placed on the sphere. The nature of this polyhedron depends upon how the points are distributed over the sphere. In the polyhedra shown here, the placement of dots was random but subject to certain constraints.
43-hedron (about 35 cm across)
I wrote some software that allowed me to choose how many faces I wanted, and to regulate how evenly spread over the sphere the dots were. I could preview the resulting polyhedron, and when I saw one that I liked, the program produced a set of images of the faces of the polyhedron, with numbered tabs on them. Then all I had to do was print them, cut them out, fold the tabs, and glue them all together. This is not a task for the impatient: the 83-hedron at the top took about 3 days.
The polyhedra shown here differ principally in how evenly the dots were spread over the imaginary internal sphere. After randomly placing the dots, the program simulated repulsion between them (as if they were electric charges). The longer this repulsion process went on, the more evenly distributed the dots became. For the 29-hedron, no repulsion process was done, and for the 43-hedron, the process was allowed to continue until the dots stopped moving; presumably this is now (in some undefined sense) as regular as a 43-hedron can get.
29-hedron (about 30 cm across)
For the 29-hedron (right), I took advantage of the four-colour map theorem, which tells me that if I want to colour the faces such that no two neighbouring faces have the same shade, 4 shades of card are all I need. I leave it to you to convince yourself that if this theorem is true for flat maps, it must be true for maps on balls too. (If you don’t see where maps come into it, think of each face of the polyhedron as a country on a political map.)
None of this would have happened had it not been for a visit to Jenny Dockett to talk about her Illuminating Geometry project. It was while talking to Jenny that the idea for making irregular polyhedra came to me.
I wrote the software in Python. The internally-illuminated shapes are made out of layout paper (very thin paper), and the 29-hedron is made of thin card. I used UHU Office Pen glue (not to be confused with UHU Pen glue). This glue doesn’t wrinkle the thin paper, and dries at about the right speed, but has proved to be somewhat unreliable in humid weather.






 kilometres.
kilometres.


 grid lines per kilometre of its length. Now a mile is 1.609 kilometres, so a segment of the walk will, on average, cross
grid lines per kilometre of its length. Now a mile is 1.609 kilometres, so a segment of the walk will, on average, cross  grid lines per mile, which is very close to 2 grid lines per mile, as our rule assumes. If a mile were
grid lines per mile, which is very close to 2 grid lines per mile, as our rule assumes. If a mile were